本文最后更新于 2024-08-19T14:02:01+08:00
Policy Gradients
- 对比起
Value-based的方法(Q learning, Deep Q Network), Policy Gradients 直接输出动作,最大好处就是, 它能在一个连续分布上选取 action。
Policy Gradients 决策
- 行为不再是
Q-value来选定的, 而是用概率来选定.
Policy Gradients 更新
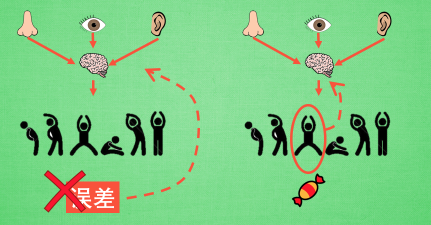
- 观测的信息通过神经网络分析, 选出了左边的行为, 直接进行反向传递, 使之下次被选的可能性增加, 但是奖惩信息却告诉这次的行为是不好的, 那动作可能性增加的幅度随之被减低. 这样就能靠奖励来左右神经网络反向传递。(回合更新)
Policy Gradients整体算法
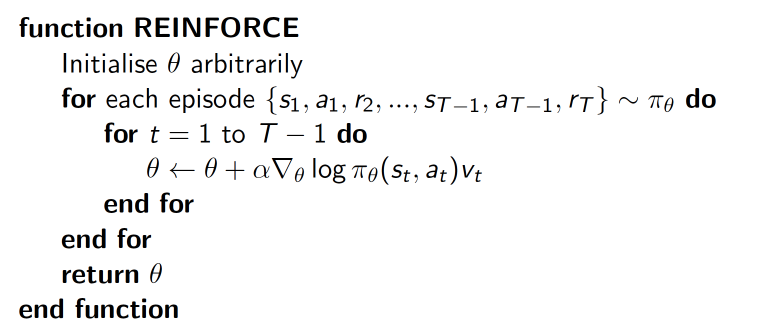
- 吃惊度:
(log(Policy(s,a))*V) 表示在 状态 s 对所选动作 a 的吃惊度, 如果Policy(s,a)概率越小, 反向的log(Policy(s,a))(即 -log(P)) 反而越大。如果在Policy(s,a)很小的情况下, 拿到了一个大的R, 也就是大的V, 那-(log(Policy(s, a))*V)就更大, 表示更吃惊, (我选了一个不常选的动作, 却发现原来它能得到了一个好的reward, 那我就得对我这次的参数进行一个大幅修改)。
Policy Gradients
https://lllzheng.github.io/2024/08/05/rl/4-Policy Gradients/